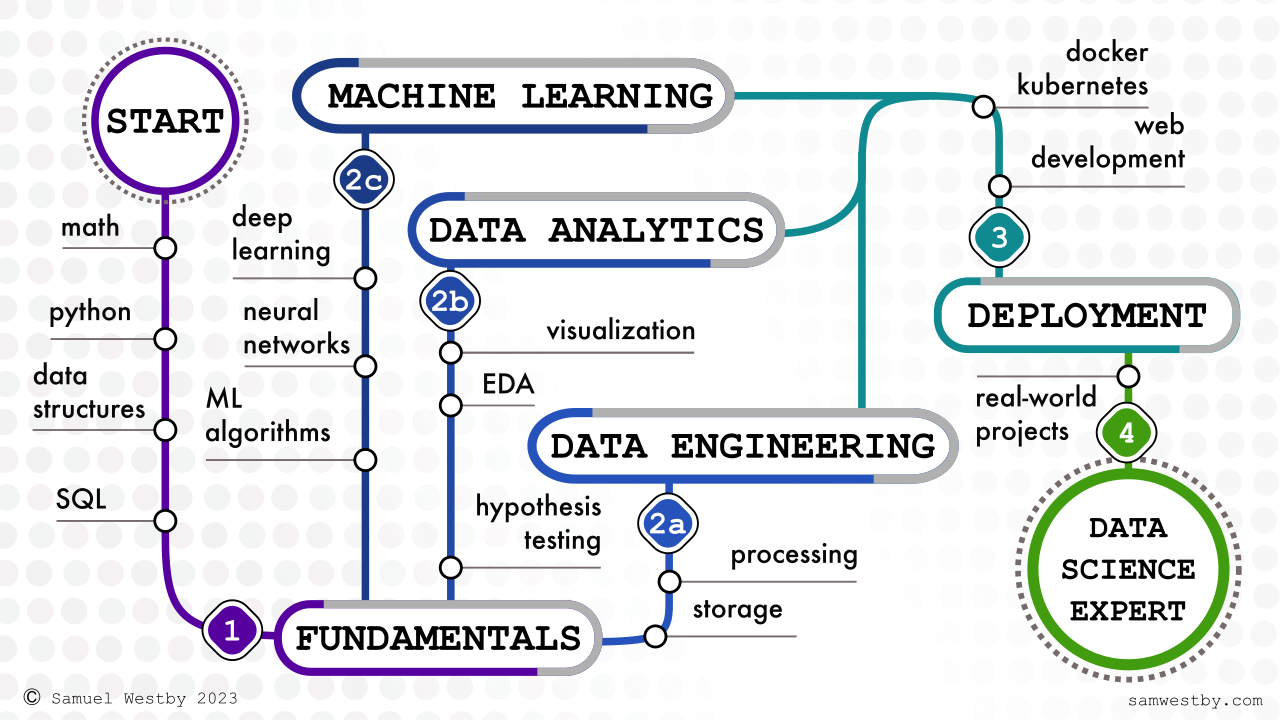
Hey there! So you're looking to become a full-stack data scientist? Well, I can definitely say that it's a challenging but achievable goal. You start by mastering the fundamentals - linear algebra, calculus, statistics, basic Python, SQL, and data structures - these are the building blocks that every data scientist should know. From there, you can choose to specialize in data engineering, data analytics, or machine learning.
February 20th, 2023
The truth is, knowing all parts of the stack (data engineering, data analytics, and machine learning) is extremely valuable, but it's also very difficult because there's so much to learn! But don't worry, by doing things, getting stuck, and learning, you'll be on your way to becoming a full-stack data scientist in no time!
Here's how to use this guide. First, master the fundamentals. Second, choose your adventure: data engineering, data analysis, or machine learning. Third, learn how to share your models using deployment strategies and web development. In each section I provide sub-sections and many resources for learning each subsection.
As a data scientist, it's easy to get lost in the technical aspects of the job, but it's important to remember that communication skills are just as critical to success. Even if the roadmap doesn't specifically mention it, being able to clearly communicate your findings and insights to a non-technical audience is a vital part of the role. It's all about making sure the work you've done gets put into action, and that requires being able to explain it in a way that everyone can understand. So don't forget about communication, even if it's not explicitly listed on the roadmap! It'll pay off in the long run. As you work through the topics below, try explaining them to your friends in a way they'll understand - the bird's eye view. A master can explain their topic to someone at any level.
4. Basic SQL and database management
1. Machine learning algorithms
3. Hackathons and competitions.
The fundamentals are crucial in becoming a full-stack data scientist because they provide the foundation for everything else that you'll need to learn. Basic math and programming concepts are essential for understanding complex data structures and algorithms, as well as building and managing databases. Exploratory data analysis, data visualization, and hypothesis testing give you the skills to understand and interpret data, and the ability to make informed decisions based on that data. Mastering the concepts below will give you a solid foundation to become a data scientist.
Math is important for data science because it provides the foundation for many machine learning algorithms and data analysis techniques. It is used for tasks such as optimizing models, solving systems of equations, and understanding the relationships between variables in large datasets.
Data scientists use linear algebra to manipulate data at a large and general scale. Many algorithms leverage linear algebra for processing acceleration.
Resources (pick one):
Data scientists use calculus for many techniques. A quite popular technique is gradient descent for model optimization. You do not need to learn the depths of calculus proofs. Just have an understanding of differentiation and integration.
Resources (pick one):
Probability and statistics allow data scientists to be certain about conclusions they draw from the data. They provide tools to make claims about truth, correlation, change, and causality.
Resources (pick one):
Basic Python is important for data science because it is a widely used and versatile programming language that is well-suited for data analysis and machine learning tasks, with a large community and many powerful libraries and tools such as NumPy, Pandas, and scikit-learn. Data scientists use Python more than any other language. Visualization is also an important tool. Start with matplotlib.
Resources (pick one):
Resources (pick one):
Data structures are important for data science because they provide a way to organize and efficiently manipulate large amounts of data, allowing data scientists to perform complex data analysis tasks and make informed decisions.
Resources (pick one):
Basic SQL and database management is important for data science because it enables data scientists to efficiently store, manipulate, and retrieve large amounts of data, which is crucial for data analysis and machine learning tasks.
Resources (pick one):
Version control is important for data science because it allows data scientists to track changes to their code, collaborate with others, and revert to previous versions if necessary, ensuring the integrity and reproducibility of their work.
Resources (pick one):
Algorithms are important for data science because they provide the basis for machine learning models and other data analysis techniques, enabling data scientists to make predictions, classify data, and identify patterns in complex data sets.
Resources (pick one):
Data Engineering provides the infrastructure for collecting, storing, and processing large amounts of data. Data engineers design and implement data pipelines, workflow management systems, and data storage systems that ensure data are easily accessible, scalable, and secure. Without the contributions of data engineers, data scientists would be unable to work with the large and complex data sets
Data storage systems provide the means for storing large amounts of structured and unstructured data and support the data processing needs of data scientists and other stakeholders. They come in many different forms.
Resources (pick one):
Resources (pick one):
Data processing frameworks, such as Pandas, Apache Spark, and Dask, provide tools for efficiently manipulating, transforming, and aggregating large datasets. This helps data scientists to work with complex data.
Resources (pick one):
Resources (pick one):
Data analytics refers to the process of examining, cleaning, transforming, and modeling data with the goal of discovering useful information, informing conclusions, and supporting decision-making.
Exploratory Data Analysis (EDA) is an approach to analyzing and understanding data by summarizing its main characteristics and identifying patterns, anomalies, and relationships between variables.
Resources (pick one):
Data scientists use visualization as a tool to effectively communicate insights and findings from complex data to stakeholders, as well as to explore and understand the relationships and patterns in the data.
Resources (pick one):
Data scientists use hypothesis testing to make conclusions about an entire population based on a sample of data.
Resources (pick one):
Machine learning is a tool to learn from data and make predictions or decisions without being explicitly programmed. It involves training algorithms on large datasets to identify patterns and relationships in the data. Data scientists use these patterns and predictions to generate insights and anticipate the future.
Supervised learning is a type of machine learning where the algorithm is trained on labeled data, meaning that the desired outcome or label is provided for each example in the training data. Unsupervised learning, on the other hand, involves training the algorithm on unlabeled data, where the desired outcome or label is not provided, and the algorithm must discover patterns and relationships on its own.
Resources (pick one):
Neural networks are a type of machine learning model that are loosely inspired by the structure and function of the human brain, and consist of interconnected nodes or "neurons" that process and transmit information. This is the foundation for deep learning and state-of-the-art ML.
Resources (pick one):
Deep learning is neural networks on steroids.This allows the algorithms to learn and make increasingly complex representations of the data.
Resources (pick one):
Deployment in data science refers to the process of making a machine learning model or data-driven solution available for use by others, often by integrating it into existing systems and processes.
Docker is a platform for building, shipping, and running applications in self-contained containers. For example, you can “dockerize” your program with a unique Python environment so anyone can run your application even if they don't have the same environment or operating system.
Resources (pick one):
Kubernetes is an open-source platform for automating the deployment, scaling, and management of containerized applications, allowing them to run and be maintained in a stable and efficient manner in production environments.
Resources (pick one):
How do you distribute your work?
Resources:
Data scientists often use web development skills to create dashboards, reports, and interactive visualizations to communicate their findings and insights to stakeholders. They also use web development to build and deploy machine learning models as web services, enabling others to access and use their models through a web interface. This is a deep rabbit hole, so start with the basics. It fits well under the Deployment section, but is so large I gave it its own section.
Data scientists use HTML, CSS, and JavaScript to create interactive dashboards, reports, and visualizations to present and communicate their findings and insights to stakeholders.
Resources:
Data scientists use REST APIs to retrieve and manipulate data from remote servers and databases
Resources:
Data scientists should learn a web development stack because it allows them to build and deploy interactive, web-based applications and dashboards to communicate their findings and insights effectively and efficiently to a broad range of stakeholders.
Resources (find what works for you):
Working on real-world projects is important in learning data science because it provides hands-on experience with solving real-world problems. It also helps build a portfolio of work that demonstrates one's abilities and skills to potential employers, which is especially important for those looking to enter the field.
By reaching out to a non-profit organization and offering your skills as a data scientist, you have the opportunity to make a positive impact while also gaining valuable real-world experience. Many non-profits have plenty of data, but may not have the resources or expertise to extract meaningful insights from it. By volunteering your time and expertise, you can work with members of the organization to analyze the data and generate insights that can inform their decision-making and help further their mission. This is a great way to build your portfolio and develop your skills while making a difference in your community. Be careful, do not oversell yourself and become a burden on the organizations you're helping. It's important to be useful.
Contributing to open-source projects is a valuable way for data scientists to develop their skills, expand their network, and give back to the community by sharing their knowledge and expertise.
Participating in data science hackathons and competitions provides an opportunity for data scientists to challenge themselves, gain new experiences, and build their portfolio by working on real-world problems and presenting their solutions to a wider audience.
Resources:
As a learner, I firmly believe in the power of doing things and getting stuck. That's how you learn best. When you actively apply what you know, it sticks with you so much better. For example, I initially learned Java, but it wasn't until I started working on a visualization project that I realized how much easier it was to do in Python. So I switched gears and dove into Python, and now I can confidently say that I have a good grasp of it. The hands-on approach to learning has always worked well for me, and I highly recommend it to others too. Best of luck on your data science journey!